On Orchestrating Parallel Broadcasts for Distributed Systems
Authors: Peiyao Sheng, Chenyuan Wu, Dahlia Malkhi, Mike Reiter, Chrysoula Stathakopoulou, Michael Wei, and Maofan “Ted” Yin.
From Sequential Leaders To Block-DAG
Traditionally, BFT protocols have relied on sequential leader-based approaches, where a single designated leader proposes operations for the next available slot in the sequence (e.g. PBFT, HotStuff etc.). Recent advancements have moved towards parallel proposing in block-DAG protocols, allowing multiple nodes to propose simultaneously, thereby increasing throughput. Examples include SwirlDS, Blockmania, Aleph, and Narwhal/Tusk.
Despite these advances, both sequential leader-based and block-DAG protocols implicitly assume that transactions will settle in the next available slots, and these slots are allocated evenly to all active participants, despite their heterogeneous performance.
Our recent work introduces a concept called “ticketing” to explicitly manage slot allocation for proposed transactions, enhancing the orchestration of atomic broadcasts in distributed systems.
Ticketing: Separating Finalization Order from Consensus
The focus of ticketing is on performance, aiming to distribute the opportunities to propose transactions in a way that promotes parallel processing and reduces delays caused by slower or malicious nodes.
So what are the key properties of a successful ticketing scheme? We begin identifying them by analyzing and comparing the pros and cons of two basic approaches to ticketing: unmanaged and managed.
- Unmanaged ticketing: An unmanaged scheme is distributed. Nodes apply a local rule based on common information to determine who can propose into the next slot(s), one group of slots at a time. Examples include round-robin scheme, randomized leader election, etc.
- Managed ticketing: In a managed scheme, a “ticketing-server” assigns slots in advance of proposing. The server can dynamically adjust to network conditions and participant behavior.
In both regimes, settling can be processed simultaneously on all ticketed slots.
Desired Characteristics of a Ticketing Scheme
To better assess different ticketing schemes and refine our design approach, we have identified a set of properties that encapsulate our expectations for an effective ticketing system. Briefly, a well-designed ticketing regime should be efficient, robust and versatile: it should allow multiple nodes to propose transactions simultaneously, while preventing faster nodes from monopolizing resources or letting malicious nodes hinder overall progress; it should be capable of handling both good and unstable conditions.
Good-case properties
We aim for a design that works well in common, good conditions (steady state), where the network is stable and nodes operate without faults. In steady state setting, we would like our scheme to allocate each slot to a single node, thus avoiding any conflicts (referred to as contention-free allocation). We stick with this strategy even when faced with faults and address it with reputation management, as we will see below.
Furthermore, we expect the slot allocation to dynamically respond to varying demands and resource availability — such as payload sizes, network bandwidth, and computational power — which may be unevenly distributed across the network. This dynamic adjustment is governed by the principle of meritocracy, where slots are allocated based on merit and current network needs.
Unstable-case properties
On the other hand, in faulty scenarios, we can strive to limit the negative impact and minimize the resource waste caused by network instability or node failures. To address resource waste in such scenarios, we introduce the concept of slot utilization. This metric, inspired by the leader utilization in Carousel, aims to limit the number of skipped slots (committed with an empty ⊥ value) once the network stabilizes and under crash-only failures.
Additionally, we consider the overall chain quality of the distributed log, maintaining a healthy proportion of slots controlled by correct nodes under stable network conditions. The ticketing process also incorporates a sliding window mechanism for pending proposals, which captures the inherent parallelism of the system. The size of this window is crucial, as it must be carefully balanced to facilitate smooth operations while avoiding bottlenecks in unstable conditions.
In summary, the properties we prioritize when designing the ticketing regimes are:
- Contention-free allocation: Assigning each slot to an individual node to prevent conflicts.
- Meritocracy: Intelligently allocating of slots based on the specific resources and contributions of different nodes.
- Slot utilization: Maximizing the efficiency of resource use during network recovery phases.
- Chain quality: Ensuring a majority of reliable nodes contribute to the transaction log.
Intuitively, managed ticketing regimes outperform unmanaged ones in terms of good-case properties, since the ticketing-server has access to real-time slot demands of different nodes and can make adjustments to the allocation strategy. However, in less ideal conditions, unmanaged ticketing regimes offer stronger safeguards, as they do not rely on a central server that could potentially be compromised. The inherent fairness of unmanaged ticketing also prevents any single adversary from gaining excessive power. These considerations led us to explore a hybrid approach, combining the strengths of both managed and unmanaged ticketing, potentially offering enhanced performance and resilience across a variety of network conditions.
A Hybrid Ticketing Regime
We propose a Hybrid Ticketing Regime (“HTR”), a flexible scheme that alternates between managed and unmanaged ticketing based on the current network conditions. This adaptability allows the system to maximize resource efficiency and throughput in stable conditions, while enhancing resilience and maintaining liveness during periods of instability.
The system model involves a network of 𝑛 nodes, up to𝑓 of which may be faulty. Nodes communicate under a partially synchronous model with authenticated channels and public identities. The replicated log structure ensures consistency through atomic broadcast. Liveness is facilitated by a pacemaker module that synchronizes slot timers across nodes, ensuring that proposals are finalized or ejected efficiently. One core feature of the model is that it supports out-of-order finality, that is, slots can be finalized independently of their slot in the global sequence, enabling parallel processing. A slot is committed once all preceding slots are finalized. A skipped slot is a slot committed with an empty ⊥ value.
The dual regime of the protocol works as follows:
- Epoch: A preset number of contiguous slots, 𝐿, are grouped into an epoch, with 𝐾 epochs processed concurrently. The protocol adaptively chooses a ticketing regime for each epoch.
- Initial phase: The first 𝐾 epochs start with unmanaged ticketing regime (“UTR”). The protocol maintains a candidate set in each epoch of eligible proposers, initialized by a set containing all nodes.
- Condition-based switching: The ticketing regime of epoch 𝑖 +𝐾 is determined upon commitment of all slots in epoch 𝑖, based on the following criteria.
- UTR Condition: UTR, in which the slots are assigned according to the candidate set in a round-robin manner, is used if either one of the following conditions holds:
- (a) there exists at least one skipped slot in epoch 𝑖, or
- (b) the the number of distinct “active” senders, who have at least one proposed slot committed in epoch 𝑖, is less than 2𝑓+1.
- MTR Condition: Managed Ticketing Regime (“MTR”) is employed when conditions are good (none of (a) or (b) holds), with a ticketing-server selected at random from the candidate set. The ticketing server accepts requests from other nodes and sends back certificates for them to propose.
- UTR Condition: UTR, in which the slots are assigned according to the candidate set in a round-robin manner, is used if either one of the following conditions holds:
- Updating candidate set: The candidate set is updated after every unmanaged epoch based on active participation, ensuring a minimum of 2𝑓+1 proposers to maintain chain quality. The candidate set for epoch 𝑖+𝐾 is updated to the set of “active” senders from epoch 𝑖 (if 𝑖 uses UTR), containing all senders with at least one proposed slot committed in epoch 𝑖. In situations where there are not enough active senders, the candidate set is reset to include all nodes.
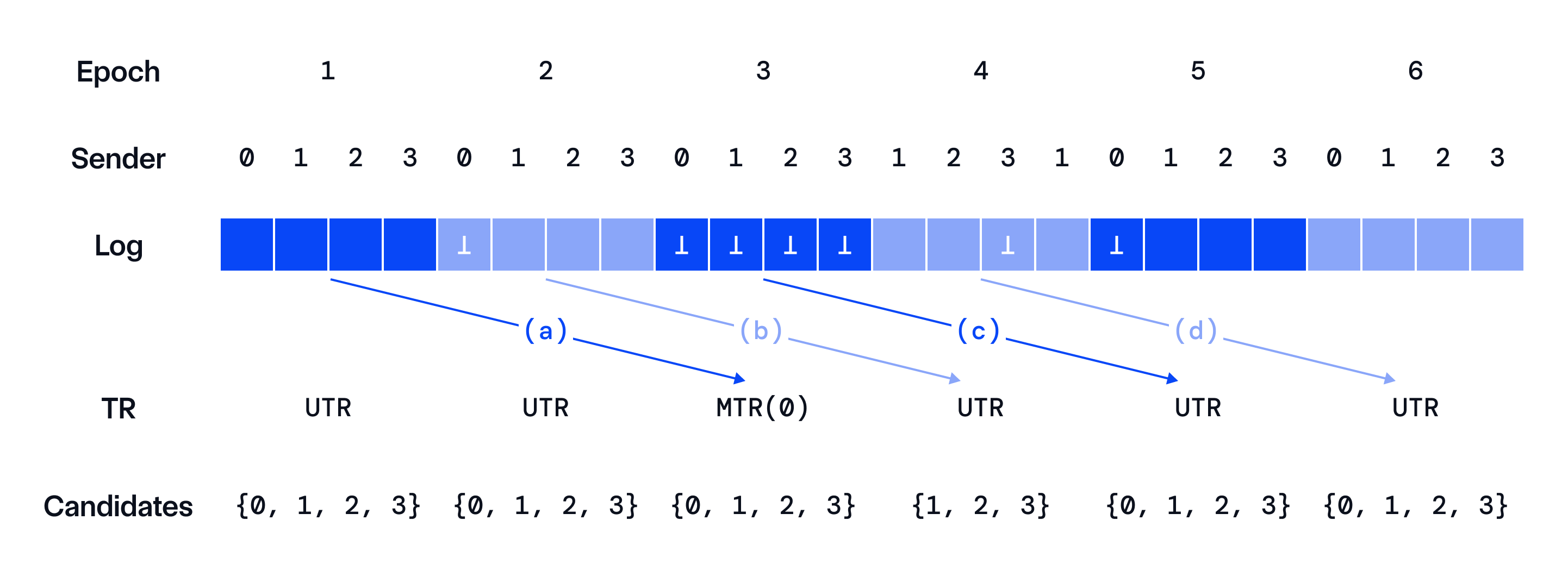
The figure below shows an example with six epochs, 𝑛 = 4, 𝐿 = 4, 𝐾 = 2. Log slots with ⊥ are skipped slots and others are committed with non empty values. The example shows four possible updating rules:
- (a) epoch 3 uses MTR since no slots are skipped in epoch 1;
- (b) epoch 4 keeps using UTR since one slot is skipped in epoch 2 and the candidate set is updated to exclude node 0
- (c) though all slots in epoch 3 are skipped, the candidate set remains the same since epoch 3 uses MTR;
- (d) the candidate set is reset to the full group of nodes in epoch 5 since epoch 4 adopts UTR and has only 2 active senders.
Comparative Analysis
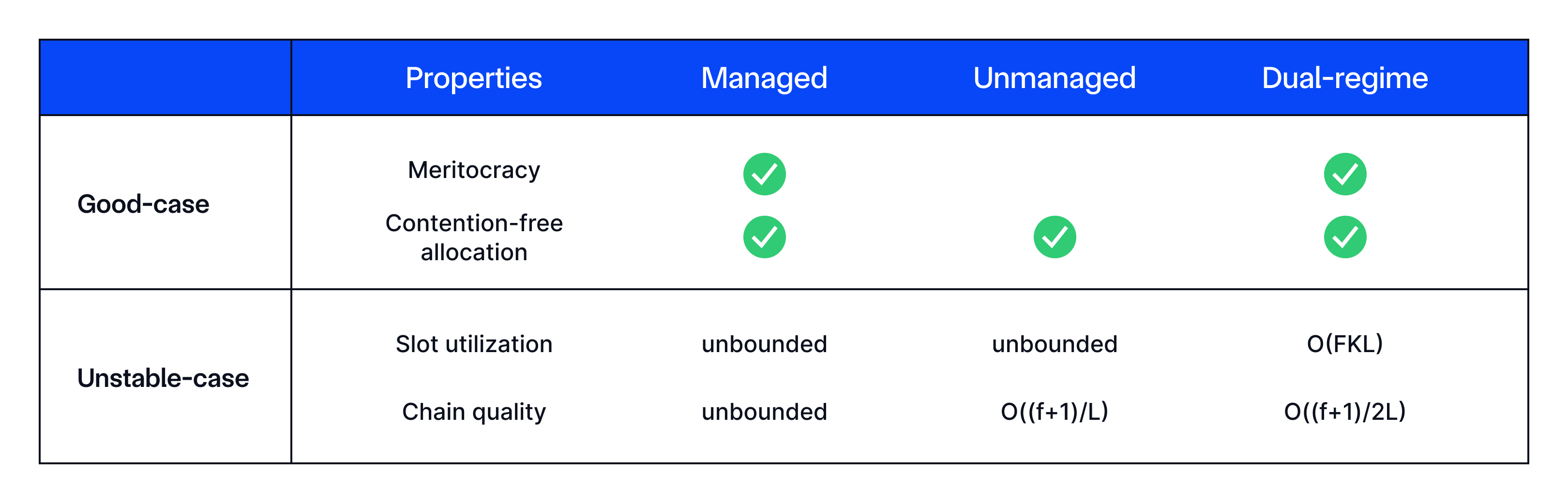
The comparison of our HTR and the basic managed / unmanaged regimes are summarized in the table below. The managed ticketing regime naturally supports meritocracy but may suffer from unbounded skipped slots if the ticketing-server itself is compromised. As such, it does not ensure slot utilization or maintain chain quality. The unmanaged scheme ensures even distribution and robustness against attacks, thereby providing good chain quality.
Our hybrid approach synergizes these methodologies, improving slot utilization through dynamic updates of the active sender set and preserving chain quality by periodically reverting to unmanaged epochs during unstable-case periods. By integrating parallel epoch processing, the HTR also ensures that undecided ticketing phases do not impede overall progress, offering a balanced, robust solution for the ticketing problem.
Performance Evaluation Summary
We implemented and compared various ticketing regimes across a set of nodes that vary in their processing and network speeds. The evaluation highlights that managed ticketing regimes work better in heterogeneous networks by dynamically adapting to fluctuating conditions and varying workloads.
Our hybrid ticketing approach combines the flexibility of managed ticketing with the robustness of unmanaged scheme, delivering enhanced throughput and reliability. Key observations are summarized as follows:
- Static Heterogeneity:
- Setting: We set up 3 faster nodes, 1 slower node for the whole experiment.
- Observation: Allocating slots to a single, fast node (UTR with a single candidate) yields the highest throughput. When all nodes participate equally (UTR with all nodes as candidates), the overall system performance is constrained by the slowest node. MTR addresses this by dynamically allocating more tickets to faster nodes, demonstrating the meritocracy.
- Dynamic Heterogeneity:
- Setting: To further test adaptivity, we run 4 consecutive phases on 4 nodes starting with the same initial setup. In each phase, we slow down a different node by idling a half of its available CPU cores.
- Observation: While UTR results in lower performance due to its inability to consistently identify the “fastest” node, MTR achieves nearly optimal performance by adjusting ticket allocation based on real-time performance metrics.
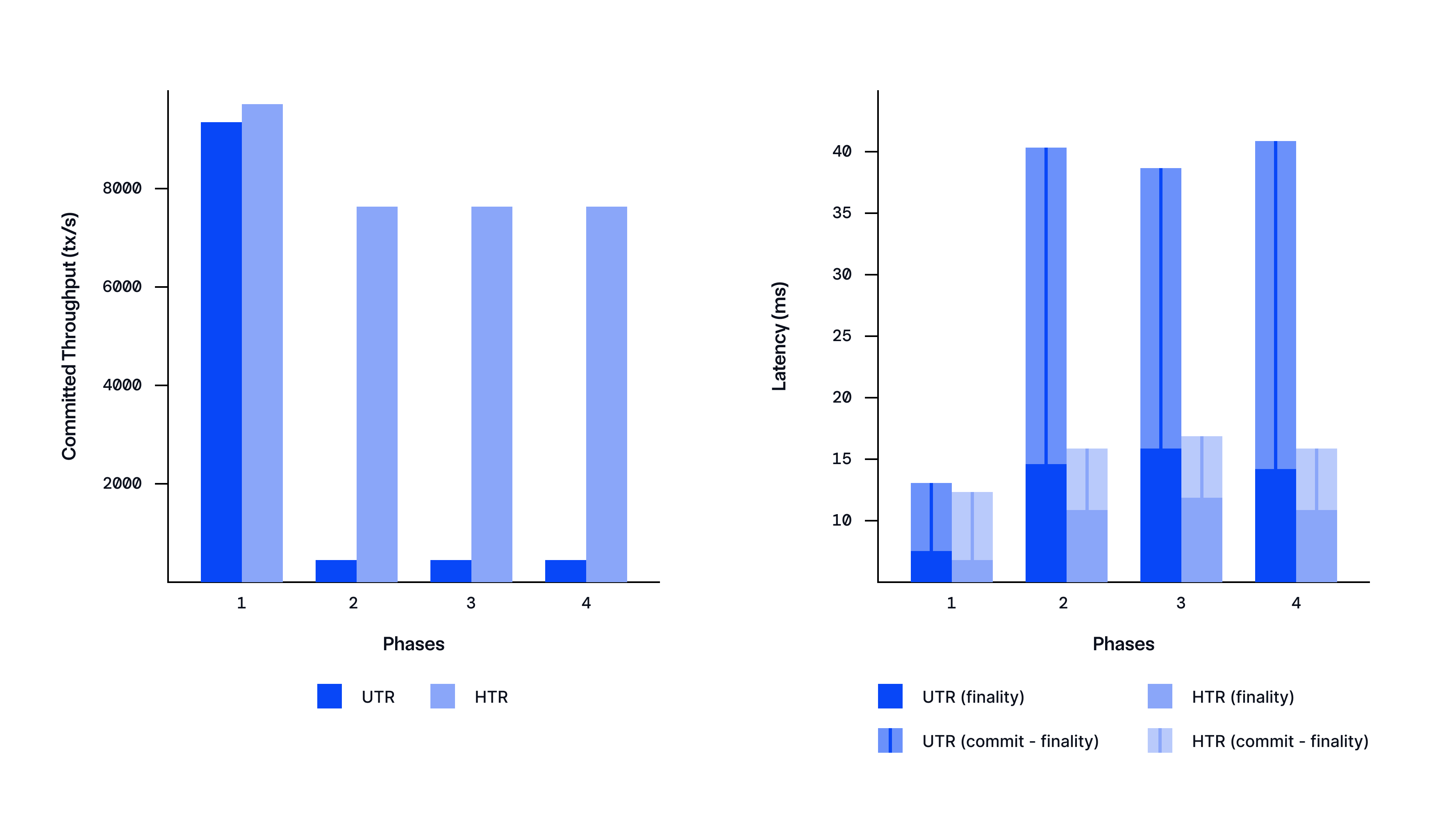
- HTR’s Fault Tolerance:
- Setting: To demonstrate the resilience of HTR in handling node failures, we run 4 consecutive phases on 4 nodes starting with the same initial setup. Then in each phase, one different node becomes faulty (other nodes are correct). The faulty node will not propose slots even it is assigned with tickets.
- Observation: The figure below compares the throughput and latency of different regimes in the dynamic faulty setting. HTR achieves superior performance in all phases.
Readings
- Leemon Baird. The swirlds hashgraph consensus algorithm: Fair, fast, Byzantine fault tolerance. https://www.swirlds.com/downloads/SWIRLDS-TR-2016-01.pdf
- George Danezis and David Hrycyszyn. Blockmania: from block dags to consensus. https://arxiv.org/abs/1809.01620
- George Danezis, Lefteris Kokoris-Kogias, Alberto Sonnino, and Alexander Spiegelman. Narwhal and tusk: a dag-based mempool and efficient bft consensus. https://arxiv.org/pdf/2105.11827
- Adam Gągol, Damian Leśniak, Damian Straszak, and Michał Świętek. Aleph: Efficient atomic broadcast in asynchronous networks with byzantine nodes. https://arxiv.org/abs/1908.05156
- Miguel Castro and Barbara Liskov. Practical Byzantine Fault Tolerance, pmg.csail.mit.edu/papers/osdi99.pdf
- Maofan Yin, Dahlia Malkhi, Michael K Reiter, Guy Golan Gueta, and Ittai Abraham. Hotstuff: Bft consensus with linearity and responsiveness. https://arxiv.org/abs/1803.05069
- Shir Cohen, Rati Gelashvili, Lefteris Kokoris Kogias, Zekun Li, Dahlia Malkhi, Alberto Sonnino, and Alexander Spiegelman. Be aware of your leaders. https://arxiv.org/abs/2110.00960



