Build It Super Simple: Introducing Single Broadcast Consensus on a DAG
Authors: Dahlia Malkhi, Chrysa Stathakopoulou, Ted Yin
After carefully breaking down the consensus problem, designing a protocol allowing parallel transmissions, high-throughput and low-latency becomes easier than ever, if one finds the right abstraction that is both powerful and simple.
Today we introduce a single-broadcast consensus protocol on a DAG that simplifies the heck out of “DAG-based” consensus, and exhibits reduced latency by several network trips compared to existing DAG-based approaches. The consensus logic is a thin layer over a novel broadcast primitive called Byzantine Broadcast With Commit-Adopt (BBCA) that leads to a single-broadcast consensus protocol referred to as “BBCA-CHAIN: One-Message, Low Latency BFT Consensus on a DAG”.
The term “DAG” (Direct Acyclic Graph) captures a transport substrate that guarantees causal ordering of broadcast delivery. BBCA-Chain has very few constraints on the DAG construction, maintaining excellent throughput by allowing parallel block broadcast. While prevailing DAG-based approaches can support parallel broadcasts, they come with a complicated design with multiple invocations of some multi-step broadcast primitive and suffer from unnecessary latency. BBCA-Chain is a single-broadcast protocol on a DAG that simplifies the consensus logic and at the same time reduces latency.
We first explain how the BBCA primitive differs from previous broadcasts.
BBCA is built over a causally-ordered Byzantine Reliable Broadcast (BRB) primitive for asynchronous systems with up to $f < n/3$ Byzantine nodes. If one peeks inside a BRB protocol, it is apparent that $f+1$ honest nodes must become locked on a unique value $v$ before the broadcast can commit $v$ at any node. The BBCA extension over BRB is an active Commit-Adopt probing API. Probing stops a node from further participating in the broadcast protocol and reports whether it has already locked a value. Probing is a local action (no communication), hence, importantly, BBCA can be implemented with the same communication complexity as BRB while providing the following guarantee:
- If any node commits $v$ in a BBCA-broadcast, then there exist $f+1$ honest nodes such that if any one of these nodes actively probe the BBCA protocol, it will return
<BBCA-adopt,$v$>. Said differently, if $2f+1$ probes return<BBCA-noadopt>, then it is guaranteed that no commit occurs.
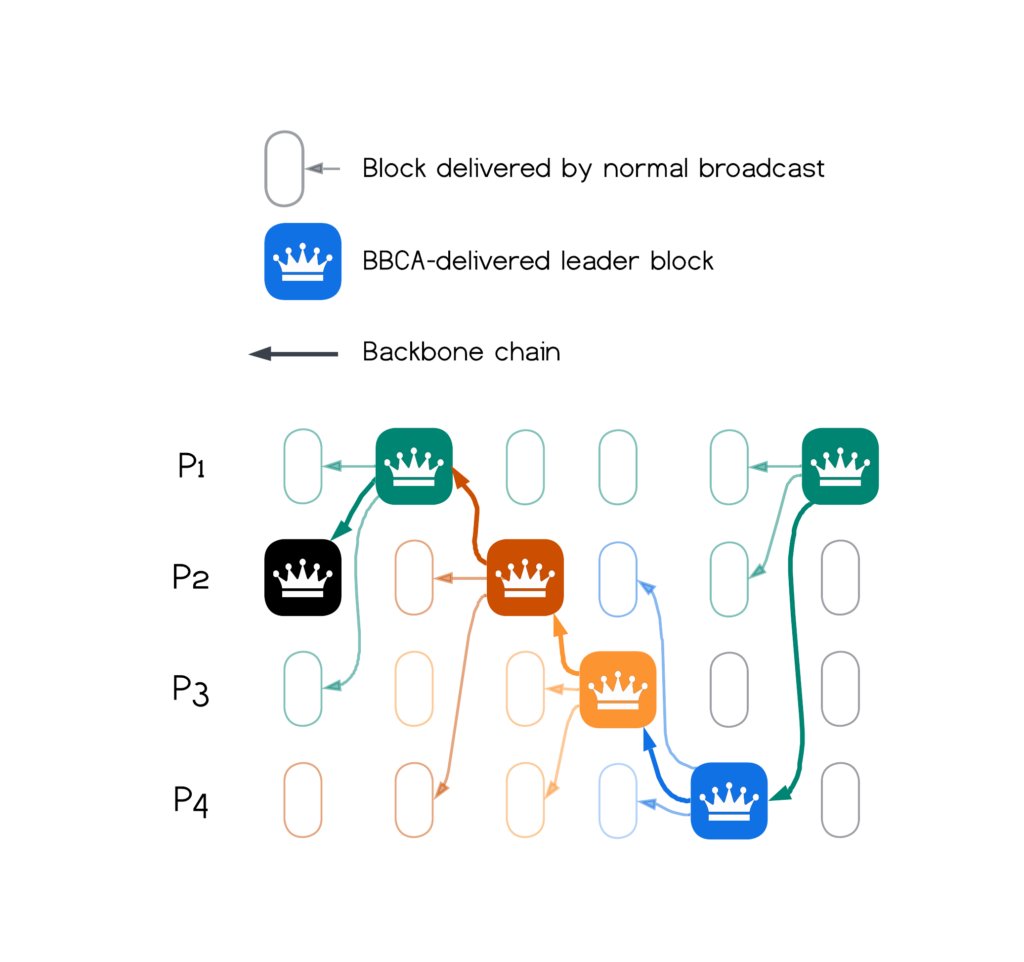
We now briefly touch on how BBCA powers BBCA-Chain, accomplishing a single-broadcast consensus protocol on a DAG. The DAG in BBCA-Chain forms a chained backbone of leader-blocks that reference each other and are broadcast via BBCA. Leader-blocks can become committed by themselves, without any additional votes or DAG layering, simply using BBCA to send the blocks. Since the local DAGs of nodes in a distributed system may evolve differently, the Commit-Adopt feature of BBCA preserves the safety of committed leader-blocks. For high throughput, non-leader blocks are broadcast in parallel using best-effort broadcast. These blocks become committed by being transitively referenced from the backbone, similar to “uncle blocks” in Ethereum. Figure 1 below depicts BBCA-Chain.
For a detailed description, see our whitepaper “BBCA-CHAIN: One-Message, Low Latency BFT Consensus on a DAG” on the ArXiv.
Technical Description
State-Machine-Replication and the Consensus Problem
Briefly, in the celebrated State-Machine-Replication (SMR) approach, a network of validator nodes form a growing totally ordered log (or “chain”) of transactions.
Data-availability. Most practical systems (e.g., PBFT:1999) batch transactions into blocks and handle data dissemination separately from the ordering protocol. In recent systems like DispersedLeder:2021 and HotShot:2023, blocks are formed after a smart transport pre-disseminates transactions and obtains a certificate of data-availability for them. Whenever a node is ready to send a block, it assembles multiple certificates into a block, adds references to previously delivered blocks, and tries to append the block to the total ordering. Managing data availability is out of scope in this post, which focuses solely on the block ordering problem.
During periods of stability, transmission delays on the network are upper bounded, but occasionally the system may suffer unstable periods. This is known as the partial synchrony model. The strongest resilience against Byzantine faults which is possible in this setting is $f$-tolerance, where $f < n/3$ for a network of $n$ validators.
DAG-Based Consensus
Causal Broadcast. A transport substrate that guarantees causal ordering of broadcast delivery forms a Direct Acyclic Graph (DAG). Note that totality (or reliability) is not necessarily required by the DAG broadcast per se.
A lot has been written about the adventage of DAG-based solutions for consensus (e.g., see BFT on a DAG:2022). In particular, it allows all nodes in the network to propose (blocks of bundled) transaction references independently and in parallel. Each node broadcasts a block carrying a useful payload that eventually becomes totally ordered in a committed sequence of transactions.
Consensus on a DAG via a Chained Backbone. In DAG-based consensus, agreement is reached on a chained backbone of blocks. Additional blocks become committed deterministically by being referenced from the backbone, similar to “uncle blocks” in Ethereum, as depicted in Figure 1 below: “crowned” blocks form the chained backbone. Each crowned block references a causal frontier that is committed with its (color-coded) transitive causal predecessors jointly with the crowned block. The batch of committed blocks is internally ordered using any deterministic rule. Note that each node may have blocks delivered in different order into its local DAG, but ordering decisions reached independently by interpreting local DAGs must be consistent.
Latency on a DAG. Prevailing DAG-based approaches are built on a Consistent Broadcast (CBC) foundation, namely, guaranteeing at the transport level that senders cannot equivocate. However, they treat the CBC primitive as a black-box way to broadcast/disseminate blocks, which leads to a complicated design with multiple specialized layers of CBCs and incurs unnecessary latency. In particular, protocols like Tusk:2021, DAG-Rider:2022, Bullshark:2022, Fino:2022 require multiple layers on the DAG for each individual backbone block to become committed. In some systems, each layer requires $2f+1$ CBCs and poses additional constraints on advancing layers (see Figure 4 in the Analysis discussion below).
If we peek into the CBC primitive, it shares a similar multi-step communication pattern and core properties with phases in protocols like PBFT/HotStuff. Therefore, it seems like a simple solution should be possible, since each block in a DAG itself is CBC broadcast. Indeed, we proceed to describe how BBCA enables simpler and faster DAG-based solutions. Compared with state-of-art DAG-based consensus protocols, BBCA-Chain brings down the latency of the best-known methods by several network trips, as well as simplifies the heck out of DAG-based consensus protocols.
First, we define BBCA in more detail.
BBCA
BBCA is built over a causally-ordered Byzantine Reliable Broadcast (BRB) primitive. A sender can invoke BBCA-broadcast($v$). Validator nodes may incur BBCA-commit($v’$) for a unique value $v’$, and if the sender is honest, $v == v’$. BBCA-commit() maintains causal ordering of broadcast deliveries.
Inside BBCA, $f+1$ honest nodes must become locked on a unique value $v$ before BBCA-commit($v$) is possible at any node. The key novel feature of BBCA is an interactive Commit-Adopt API allowing nodes to actively probe via BBCA-probe() at any time whether they are already locked. Probing stops a node from further participating in the broadcast protocol, with one of two return values, <BBCA-adopt,$v$> or <BBCA-noadopt>. Actively probing has the following guarantee:
- If a
BBCA-commit($v$)event is possible, then probes by at least $f+1$ honest nodes return<BBCA-adopt,$v$>. Said differently, if $2f+1$ probes return<BBCA-noadopt>, then it is guaranteed thatBBCA-commit()does not occur.
Probing is a local action (no communication), hence importantly, BBCA can be implemented a thin shim on top of BRB, without incurring any extra communication complexity. We have implemented BBCA (BRB) via an all-all regime a la Bracha Broadcast:1987, since nodes broadcast blocks in parallel anyway and they can piggyback BBCA echoes on them. Another approach is a linear regime a la Random Oracles in Constantinople:2002.
The intuition behind Commit-Adopt is a familiar notion at the heart of consensus solutions, named firstly (as far as we know) in Round-by-round Fault Detectors:1998. In the context of BBCA, it stipulates that a broadcast can commit only after a quorum has locked it. Although many forms of broadcasts have been formulated, including gradecast with multiple grades of output (e.g., see Flavors of Broadcast:2019), to our knowledge no previous broadcast primitive has been formulated with a Commit-Abort guarantee.
BBCA-Chain
BBCA-Chain has a simple logic that chains individual BBCA broadcast invocations (known as “leader-blocks”) into a backbone of consensus decisions on the DAG. Each BBCA broadcast becomes a committed link in the backbone by itself, without further votes or DAG layers. Nodes can use best-effort causal broadcast (“broadcast”) to transmit non-leader blocks, completely independently and in parallel. That is, only leaders employ BBCA broadcast to commit a block to a sequenced backbone. (CBC’ing non-leader blocks is not required for correctness in BBCA-Chain. It may be used for other reasons and incur an additional communication step per block, still retaining an overall substantially lower latency than existing DAG-based protocols.) When a leader-block becomes committed, a batch of blocks determined by the causal frontier it references becomes committed jointly with it, as depicted below.
Protocol
BBCA-Chain is a view-by-view protocol. Each view reaches a consensus decision in a single BBCA step. The entire protocol logic is captured in Figure 2 below.
More specifically, a leader-block in view $v$, $B_v$, is posted via BBCA, such that a BBCA-commit($B_v$) event commits $B_v$ to the chained backbone immediately, without further votes or waiting for additional DAG layers. All blocks referenced from the backbone and their predecessors become committed as well.
In order to preserve the safety of a decision that hinges on a single BBCA-commit( $B_v$), the next view’s leader-block $B_{v+1}$ must causally reference $B_v$. This is ensured by harnessing the Commit-Adopt feature of BBCA. Figure 2 illustrates the two paths in which a leader-block can become committed, a Fast path via a direct BBCA-commit() or an Adopt path. When validators enter view $v$, they start a view timer. If they deliver $B_v$ then they broadcast a block that causally follows it and advance to view $v+1$. Otherwise, eventually they time out and invoke BBCA-probe(). The response at a validator is either <BBCA-adopt,$B_v$> or <BBCA-noadopt>. The validator embeds the response in a broadcast– marking it as a complaint on view $v$–and advances to view $v+1$. Note that when a leader-block $B_v$ is embedded in a complaint, the complaint-block inherits $B_v$’s causal predecessors. This is in addition to the complaint-block’s own causal predecessors that transitively include a leader-block or a complaint-block on earlier views.
The leader-block $B_{v+1}$ of view $v+1$ must reference $B_v$ or $2f+1$ validator complaint-blocks $v$. If a bad leader tries to BBCA-broadcast() a leader-block that does not meet either condition, it will not pass validation and cannot become BBCA-commit()ed.
The key observation is that the BBCA Commit-Adopt scheme guarantees that the Fast path and Adopt path are consistent, as depicted in Figure 2 below. That is, even if BBCA-commit($B_v$) occurs on one validator and another validator sees $B_{v+1}$ causally following $2f+1$ complaints, both cases commit the same sequenced backbone prefix. This is guaranteed by the quorum intersection between $2f+1$ complaint-blocks and probed results.
To summarize, when a validator enters view $v$ it acts as follows:
- Each validator (including the leader) starts a view-timer (hourglass in Figure 2) for a predetermined duration for the leader-block of view $v$ to be
BBCA-commit()ed. - Each (non-leader) validator can immediately proceed to broadcast regular blocks. BBCA-Chain does not impose any additional constraints on growing the DAG with non-backbone blocks, so a system employs its own heuristic on when to broadcast.
- The leader (predetermined for view $v$) waits for the earlier one of the following two conditions holds before broadcasting $B_v$ via
BBCA-broadcast()as a leader-block:- Fast Path. The leader-block $B_{v-1}$ of view $v-1$ has been
BBCA-commit()ed. In this case, $B_v$ causally follows $B_{v-1}$. - Adopt Path. Complaint-blocks from $2f+1$ validators in view $v-1$, carrying a unique adopted value
<BBCA-adopt,$B_{v-1}$>or a<BBCA-noadopt>, have been delivered. In this case, $B_v$ causally follows the complaint-blocks.
- Fast Path. The leader-block $B_{v-1}$ of view $v-1$ has been
- When a validator receives a BBCA-broadcast $B_v$ carrying a leader-block, aside from formatting, it verifies if $B_v$ causally follows either: (1) a leader-block $B_{v-1}$ from view $v-1$ or (2) $2f+1$ validator complaints on view $v-1$ as in the two conditions above.
- To advance to view $v+1$, a validator waits for the earlier of two conditions to hold:
- The leader-block $B_v$ of view $v$ has been
BBCA-commit()ed. In this case, the validator broadcasts a block that causally follows $B_v$. - The view-timer has expired. In this case, the validator invokes
BBCA-probe()and embeds the response (<BBCA-adopt,$B_v$>or<BBCA-noadopt>) in a broadcast that becomes a complaint-block on view $v$ (so that the leader-block of $v+1$ may follow it).
- The leader-block $B_v$ of view $v$ has been
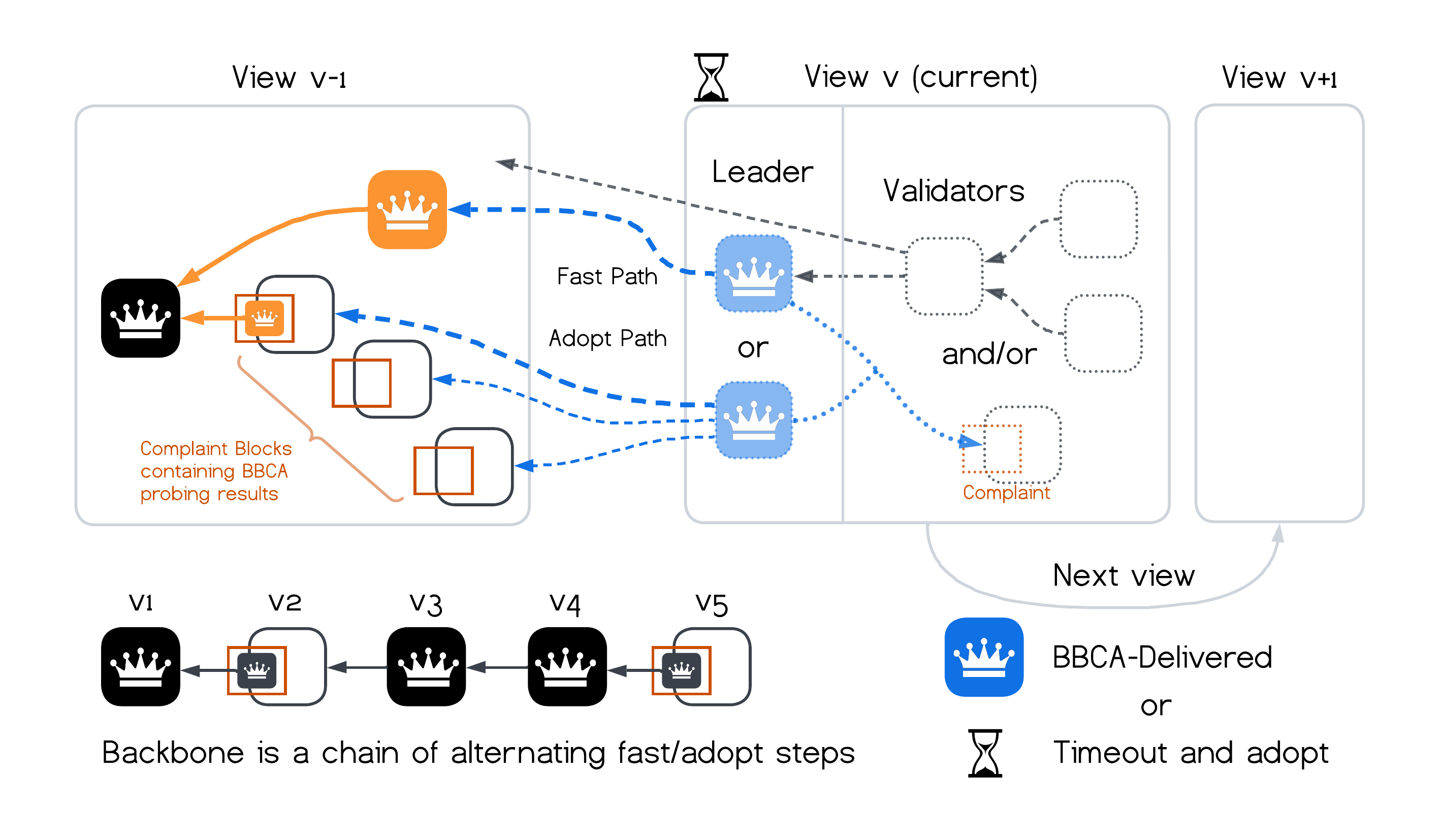
- Commit rule: Upon BBCA-commit of a leader-block, the block is committed to the BBCA-Chain without waiting for any “subsequent” blocks. Additionally, all blocks in its causal history, if not yet committed, are committed recursively (according to any predefined, system-wide, deterministic graph traversal rule such as BFS). If a block contains an adopted leader-block, it is as if the block causally follows that contained leader-block.
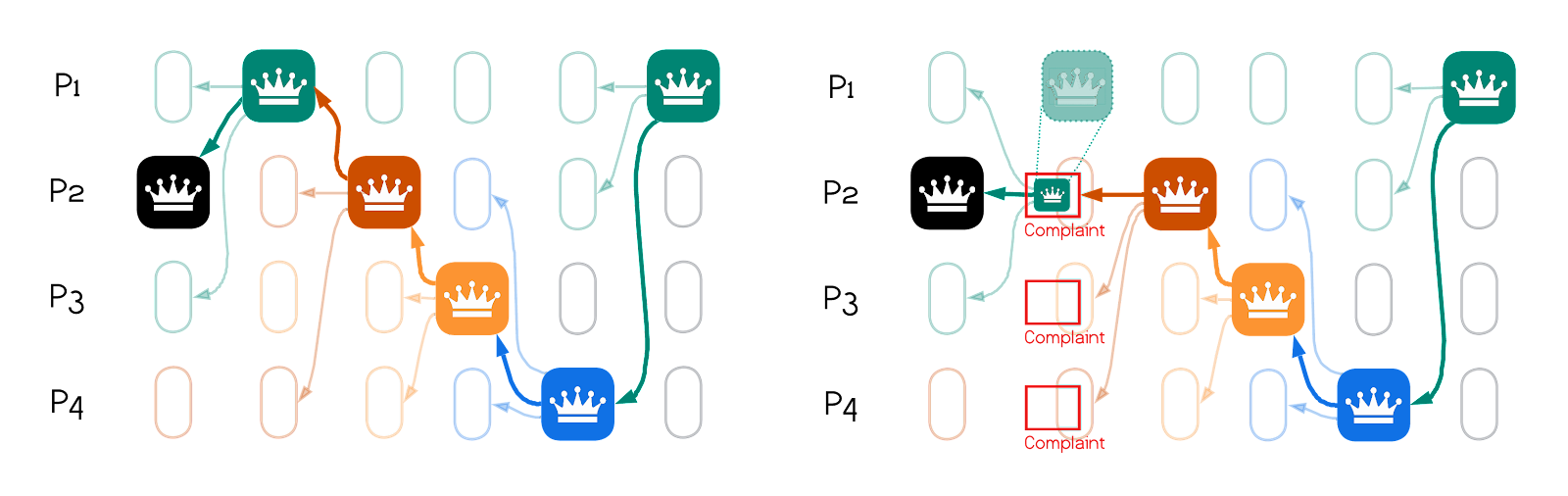
Figure 3 (left) below depicts a scenario of BBCA-Chain with six committed backbone leader-blocks. On the right is a scenario that starts the same way but BBCA broadcast of the leader of view $2$ ($P1$) only partially completes. Whenever $P2$, $P3$, $P4$ expire view $2$, they invoke BBCA-probe(), and since in the depicted scenario $P2$ adopts $P1$’s block, it becomes committed.
Analysis
Different broadcast primitives incur different communication complexities and latencies. We implemented BBCA (BRB) via an all-all regime requiring 3 network trips that can be piggybacked on parallel node broadcasts. In order to provide an apples-apples comparison, we include in our analysis a linear BRB protocol using aggregated signatures. In either form, BRB incurs one extra step compared with CBC: the extra step in an all-all regime adds one network trip and in the linear form, it adds two. The latencies of different broadcast primitives measured in the number of network trips are as follows:
| all-all | linear | |
|---|---|---|
| Best-effort broadcast | 1 | 1 |
| CBC | 2 | 3 |
| BBCA (BRB) | 3 | 5 |
Despite the extra step the BBCA (BRB) primitive incurs compared with CBC, the overall BBCA-Chain protocol requires fewer overall communication steps and thus incurs lower latencies than other DAG-based consensus solutions, since only one BBCA broadcast is needed. More specifically, BBCA-Chain non-leader blocks use best-effort broadcast, and can become ordered by a leader-block in the next view utilizing BBCA, for a total of 4 (all-all) or 6 (linear) network trips. Compared against Bullshark:2022, BBCA-Chain reduces the best-case latency to reach a consensus decision by several network trips: As explained below, in Bullshark non-leader blocks on “proposing”-layers of the DAG suffer a minimum of $4$ (linear) CBC layers, for a total of 12 network trips. Non-leader blocks on “voting”-layers incur a minimum of $3$ CBCs. (In all cases we assume that a non-leader block is timely referenced by some leader block).
| leader-blocks | non-leader blocks | |
|---|---|---|
| Bullshark | 2 x CBC | 4 x CBC (proposing-layer) 3 x CBC (voting-layer) |
| BBCA-Chain | 1 x BBCA | 1 x best-effort broadcast + 1 x BBCA |
A Brief Comparison with Bullshark
We provide a brief overview of the differences between BBCA-Chain and Bullshark, first how BBCA-Chain reduces latency, then how to remove layering constraints (for a detailed description of Bullshark, see Bullshark:2022).
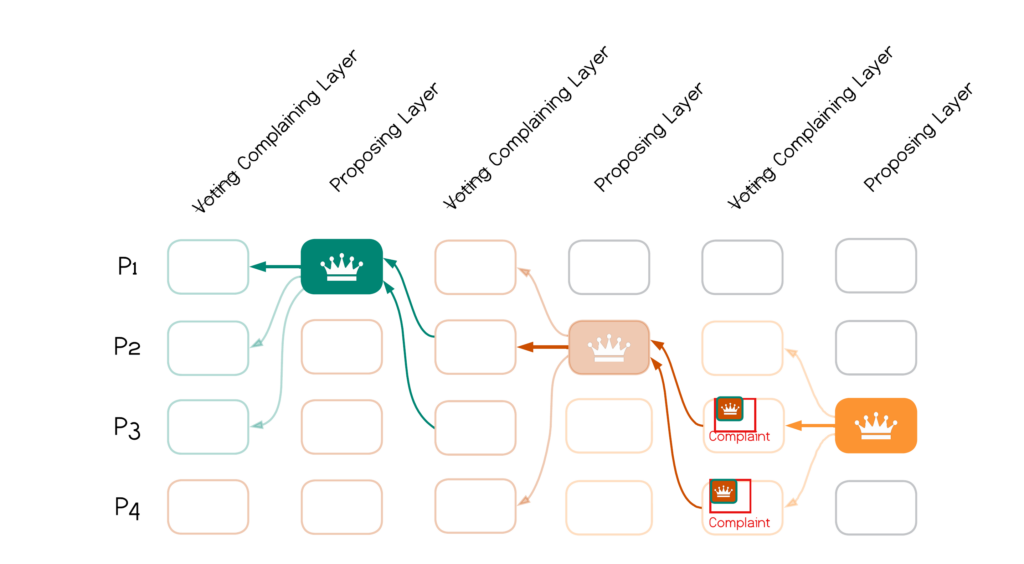
In Bullshark, each block in the DAG is sent via a consistent broadcast (“CBC”) primitive. The figure below illustrates the consensus logic: leaders broadcast proposals on even layers of the DAG. Non-leaders can broadcast blocks on both odd and even layers. Blocks in odd-layers are interpreted as votes if they causally follow a leader proposal on the preceding layer. If there are $f+1$ votes in an odd layer for a leader proposal in the preceding layer, it becomes committed. As illustrated below, it takes a minimum of 4 chained CBCs for a block to become committed
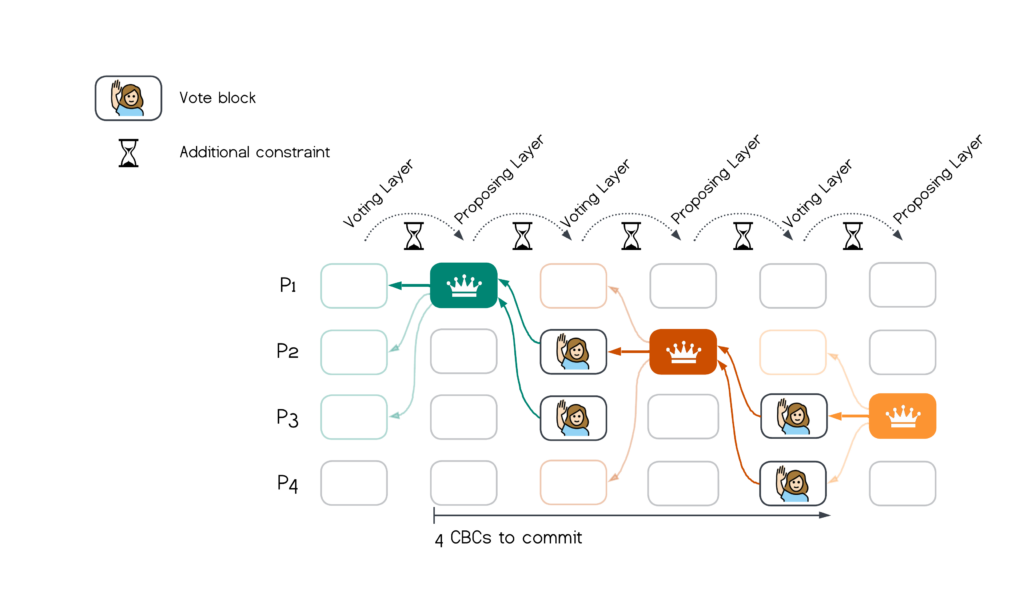
It is worth remarking that Bullshark is implemented with a (linear) CBC that takes $3$ network trips. Hence the best-case latency for blocks on proposing layers to become committed in Bullshark is 4 x 3 = 12 network trips.
Using BBCA for Leader-Blocks
The first difference is that BBCA-Chain replaces the CBC primitive by which leader-blocks are sent with a BBCA broadcast. BBCA adds a thin shim on top of CBC and overall, this step achieves a one-broadcast consensus protocol, as well as reduces latency to reach consensus decisions.
We also need to modify how a node “complains” if it times-out waiting in a “voting” layer for a leader-block: it first invokes a local BBCA-probe(), and then it embeds the result (BBCA-adopt or BBCA-noadopt) in its complaint broadcast (the one that doesn’t follow the leader proposal).
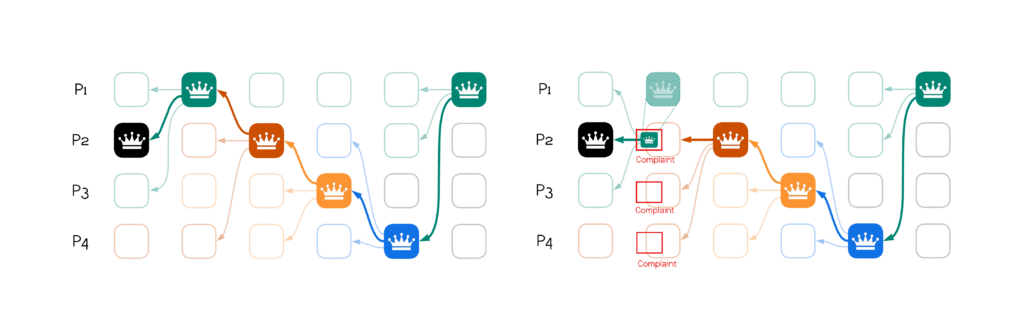
The modified version, namely Bullshark using BBCA for leader-blocks and removing voting blocks, is depicted below.
The commit rule of Bullshark remains as before, but note that a BBCA block commits by itself, without any voting blocks. When a leader-block has in its causal past an embedded leader-block, it handles the embedded information like a normal leader-block.
This change reduces the latency to commit a leader-block from $2 \times$ CBC to $1 \times$ BBCA:
- In an all-all protocol, $2 \times$ CBCs take 4 trips and BBCA 3.
- In a linear protocol, $2 \times$ CBC takes 6 trips and BBCA 5.
All commits (both leader and non-leader blocks) depend on the latency for leader-block commits, hence this save $1$ network trip to commit every block on the DAG.
We remark that because there is only one BBCA broadcast per layer, it might make sense to implement it via an all-all protocol and avoid signatures. Starting with a Bullshark implementation with a linear CBC, this would improve latency to commit a leader-block from 6 to 3.
Getting Rid of Specialized Layers
The second differences is that BBCA-Chain removes the dedicated layers for “voting”/“proposing” altogether. This requires a bit of explaining:
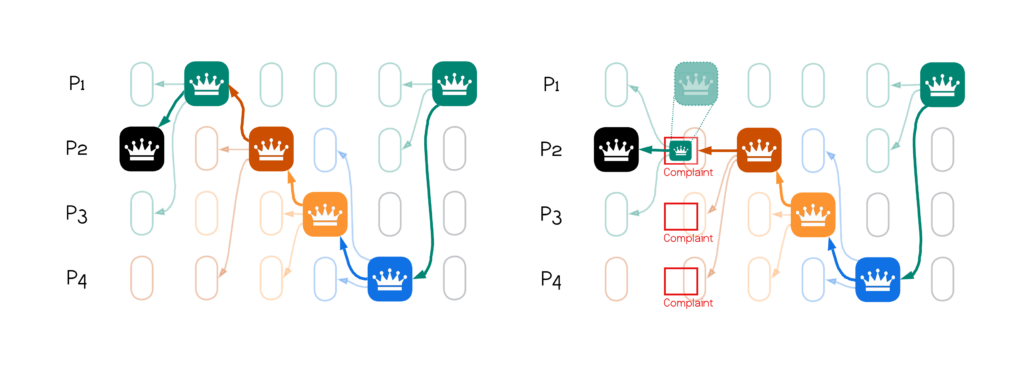
In Bullshark, voting occurs on the layer that follows a leader-block, because voting blocks must causally follow the proposal they vote for. The first modification (above) already gets rid of voting blocks, but if a node times-out waiting for a leader-block, it needs to broadcast adopt/no-adopt in complaint-blocks. The trick is that complaint-blocks can occur on the same layer as the leader-block, because there is no causality reference. This results in further latency reduction on committing non-leader blocks as depicted below: On the left, a scenario without complaints, and on the right, one layer incurs complaints.
This change reduces the latency Bullshark incurs for non-leader blocks from $4 \times$ CBC (on blocks in previously proposing-layers) to ($1 \times$ CBC + $1 \times$ BBCA). This saves–on top of one network trip saved for the leader-block to commit above–additional 2 network trips in all-all protocols, and 3 trips in linear protocols.
We remark that a similar reduction is achieved by a trick implemented in Mysten Labs DAG:2023 (Mysten Labs, private communication in 2023): it interleaves two backbones, each formed by one Bullshark instance, where both are simultaneously operating on the same DAG but have alternating proposing and voting layers. Getting rid of specialized layers achieves the same reduction but seems simpler.
Getting Rid of CBC for Non-Leader Blocks
The third difference is that BBCA-Chain does not require non-leader blocks to use CBC, because consensus on leader-blocks suffices to determine unique blocks to include in the total ordering. Bullshark needs CBC for all blocks in voting-layers, but because we already got rid of voting-blocks, there is no need to use CBC for any non-leader block.
This change allows further reduction in latency by 1 network trip against CBC that uses an all-all protocol, and by 2 network trips against a linear protocol.
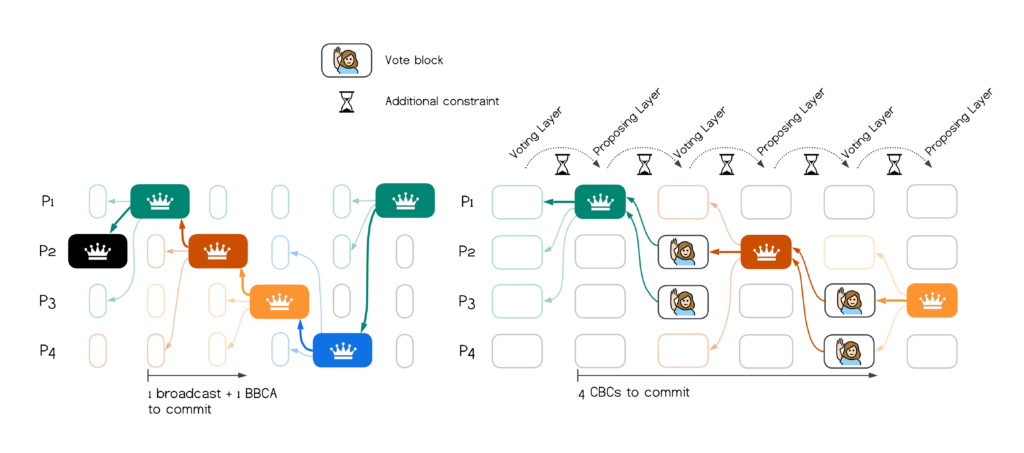
We depict non-leader blocks broadcast without CBCs via “thin” blocks below.
It is worth noting that there is a tradeoff here: using CBC for non-leader blocks may be useful to avoid keeping equivocating blocks in the DAG.
Putting 1-2-3 Together
Applying all 3 steps and using an all-all regime for BBCA broadcast, we achieve a super simple single-broadcast protocol with a best-case latency of 4 network trips. Not only is this a reduction of 8 network trips from the best-case latency in Bullshark (for blocks on proposing layers, assuming a linear CBC implementation), 4 trips is optimal latency for Byzantine consensus.
The figure below depicts the overall improvement from Bullshark to BBCA-Chain: after (left) and before (right). The relaxation of inter-layer constraints is discussed next.
Relaxing the Structured-DAG Layering
In addition to the commit latency reductions, we comment briefly on relaxing the structure-DAG layering constraints.
Bullshark operates on a Narwhal DAG:2021, which is structured in a round-based (layered) manner as introduced in Aleph:2019, requiring each layer to have $2f+1$ blocks and each block to reference $2f+1$ predecessors in the immediately preceding layer. This requirement is not needed for BBCA-Chain correctness and can be relaxed and fine-tuned by system designers to their needs. However, in order to preserve correctness of the consensus logic, relaxing the predecessor requirement must done with care.
In particular, leader-blocks at each layer must reference either the a leader-block in the previous layer or $2f+1$ complaint-blocks. In the layered-DAG of Bullshark, this requirement is enforced at the DAG level. BBCA-Chain enforces this rule inside the BBCA broadcast primitive: nodes will not acknowledge a leader BBCA-broadcast if it does not fulfill it.
We remark that system designers may choose to structure the DAG to address various other considerations. For example, a system may require $f+1$ predecessors for censorship resistance. Another system may require a constant number of predecessors to achieve certain parallelism. Additionally, systems may adaptively adjust the required number of predecessors at runtime based on their workload. Finally, structuring may also help with garbage collection and keeping node progress in sync at the network substrate level. Removing structured-layering from consensus logic shifts the fine-tuning of structuring outside the consensus logic. In particular, rigid layering requirements can be quite prohibitive in certain settings:
- Layering assumes that all correct validators generate block proposals at the same speed. This allows progressing only at the speed of the $(f+1)$‘st slowest node.
- In many blockchain settings, there is a large number of validators securing the validation responsibility over a shared transaction pool. In particular, Ethereum’s Proposer-Builder-Separation:2022 leads to a large ($>10,000$) set of validators and a small number of block builders. Forcing all validators to broadcast blocks can be prohibitively expensive in this setting.
Epilogue
The science of computing is often about creating the right abstractions that hide away complexities and allow builders to harness repeatable, reusable, powerful primitives. BBCA-Chain demonstrates the power of having a good abstraction like BBCA through a simple DAG-based consensus protocol that utilizes it and advances the state-of-art.
BBCA (pronounced ‘Bab-Ka’) is also a delicious pastry. Taking a first bite (a “biss” in Hebrew and German, or Build It Super Simple), we accomplished BBCA-Chain. Another bite is taken by BBCA-Ledger, a recent consensus protocol that employs BBCA (rather than a best-effort broadcast) for slot-level parallelism on a log. BBCA-Ledger has slightly different characteristics than BBCA-Chain and was left out of the discussion here.
Acknowledgements: We are grateful to George Danezis, Eleftherios Kokoris Kogias, and Alberto Sonnino for useful comments about earlier drafts of this post.



