Using Decentralized Storage To Build the World’s Most Censorship-Resistant Website
Most websites today follow an architecture of backend server to frontend code. But in Web3 applications, frontend code doesn’t have the same decentralization, resilience, or censorship resistance as the backend code that is secured by smart contracts. I wanted the answer to the question: How can I make a website as resilient as a smart contract?
The architecture seems easy enough:
- Create a static website that doesn’t have a server.
- Host code in a decentralized location.
- Place instructions to each decentralized location into a single spot.
To do this, we had to go down the rabbit hole of decentralized storage. And it’s understanding these different solutions that can help us create the most unstoppable website…kind of.
You can see all the code that we are going to be referencing here.
1. Make a Static Website
Since we are trying to be unstoppable, we need to make sure we have no centralized points of failure. If our website needs to make HTTPS calls to a centrally controlled server, we have created a point of failure.
So we need to create a static site, where the HTML, Javascript, and CSS files are all pulled from a decentralized storage location, and we don’t have any Javascript or server language running code to help support the site.
For anyone familiar with web development, this is a pretty trivial task. You can create a single page of HTML, JS, and CSS. Then you’re done. There are more advanced frameworks to help you do this, like Gatsby, Hugo, and Eleventy.
We decided to use the static export feature of NextJS to show you that you can do it with React or larger frameworks as well, and we created this demo site that does absolutely nothing but show you a picture of this frog and has a link to a Discord to help people with the 32-hour FreeCodeCamp Javascript & Solidity course.
If we wanted, we could still have our site interact with a blockchain like Ethereum as the backend. Having a decentralized backend wouldn’t add a layer of centralization, so we can feel safe there.
Now that we had our site, we had to figure out where to host it.
2. Host the Site: Attempt ETH
Well as a Web3 dev, my first thought was: Why not Ethereum?
Now, we could store all our data on Ethereum or another EVM chain. But however we do it, it would be both disgusting and expensive.
Instead of trying to copy-paste our folders into storage variables within our contract, a cleverer way would be to base64 encode the whole site into this one massive URI that we could store in a storage variable…or multiple storage variables.
But after a few hours of me fiddling with the gas to make it make economical sense, I gave up. Even on Arbitrum, it looked like storing all this data would have cost me at least $200. However, for smaller sites, this would be a feasible way to do it.
So instead, I created a crappy SVG of the site, base64 encoded that and posted it as an NFT on Arbitrum.
Now, before we look at my next attempt, with my base64 encoded, a method I used to make the data URI smaller and more efficient was by flattening my website code into one HTML file. This meant manually going through my `index.html` file and replacing references to other files with the base64 encoding of those files, or just copy-pasting the code into the HTML file.
This is important because we use this flattening for future attempts. So even though we decided EVM contracts aren’t the best, we still learned a lot, and we are going to come back to Ethereum at the end of this to tie it all together—so stay tuned.
3. Host the Site: Attempt dStorage
So Ethereum and other EVM chains aren’t great for storing massive amounts of data. Well, what solutions are?
Sia, Arweave, and Filecoin.
You’ll notice I didn’t include IPFS. We will talk about IPFS soon.
Arweave
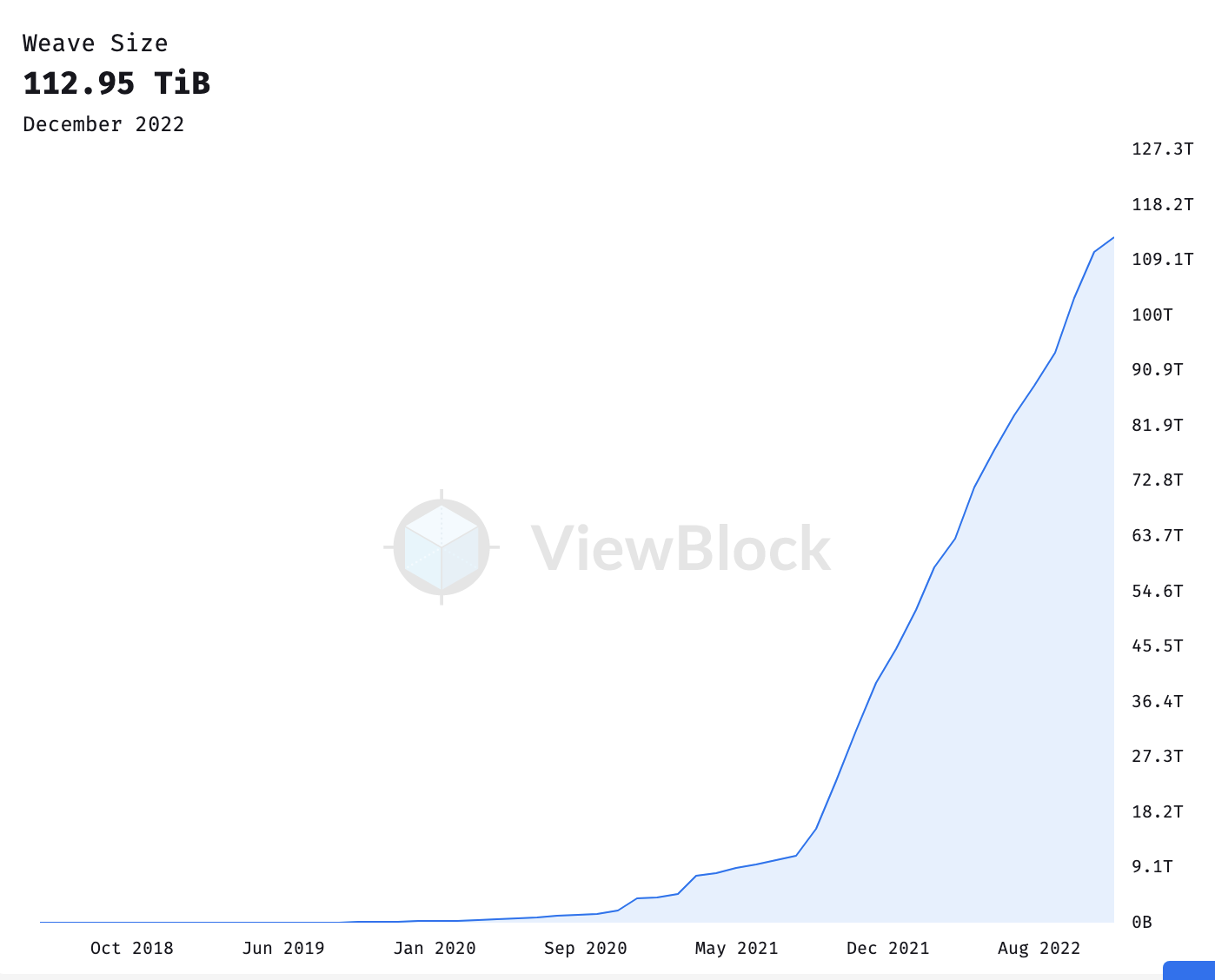
Let’s start with Arweave. Storing data on Arweave is almost exactly the same as storing data on Ethereum. Once you store the data, it’s there forever. This is called “blockchain-based data persistence,” which means every single piece of data is stored on the Arweave network. Because of this, the blockchain itself is currently around 112 terabytes at the time of recording, even after only being up for around four or five years.
So, for me to store my data on Arweave, I’d need to run an Arweave node…which I didn’t want to do, so I used a centralized tool called arkb to send the data to store my website. It’s similar to an Infura or Alchemy RPC URL for Ethereum, a sort of Arweave node as a service. For arkb, I had to flatten my site a little, as it only understands relative imports and not base64-encoded data URIs. If I ran my own Arweave node, I’m sure I could have used my data URI instead.
And boom, we can use this Arweave explorer to see the transaction we created to store our data on Arweave, and we can then use the Arweave gateway to read the data from the blockchain and render our site! All data on the Arweave blockchain is public, so remember to only update data that you’re cool with everyone seeing!
Now, a note on scale.
You might be thinking, “wow, 112 TB is a LOT of data, how is it feasible for the Arweave chain to keep growing?” Arweave has some clever consensus mechanics to make it easier to not have to have every single piece of data on every node, has done research into data storage costs, and thinks that data storage will keep getting cheaper so the growing size of the chain won’t be an issue—but this is a common problem blockchains face, called “state bloat.”
State bloat is when a blockchain has a ton of useless data that no one needs or accesses anymore, but because of the way consensus works, you need all the data to compute hashes for future data.
So the Sia and Filecoin networks took a different approach to data persistence, instead using a “contract-based” approach.
Sia
The Sia network consists of hosts who take contract agreements to store data with renters, with the contracts stored on Sia’s proof-of-work blockchain.
With Sia, I was able to get a node up and running myself no problem by going through the docs, and the blockchain is only about 40 GBs due to the chain storing the information for the agreements and not the data itself. And it even comes with a UI! I was able then to just drop our data into the UI to get a deal going with other nodes on the Sia blockchain.
Sia uses periodic challenges to force hosts to keep the data, and if they are unable to submit a proof that they have the data, they are economically punished.

Now here is where we run into our first hurdle. The Sia blockchain is a security-first chain, and our data, when stored, actually gets split up and encrypted among many hosts, with only the person who stored the data having the private key to decrypt it. So even though I can see the transaction hash of the data, only I can access it because I’m the only one who has the private key.
This is where Skynet comes in, Skynet is a tool that allows people to rent data on other peoples’ nodes, a sort of open-sourced Sia-as-a-service. If we upload our data to someone else’s Skynet portal, the portals come with a way to automatically render the sites using the hash of the folder or files we uploaded.
A major issue with this approach is that we have to trust that they are giving us good data and haven’t tampered with it. This means that the website wouldn’t be unstoppable either. If they go down, we’d lose the site. We could run our own portal and let people have access to our data, and post a proof along with our site so users can verify on their side, but users would need to have some domain knowledge to understand what’s going on.
If we want to create an unstoppable website that only we can access, like an intranet or private documentation, Sia is the perfect option.
The Sia community is working on ways to make this all much easier in the future, and I’ve had some wonderful conversations with them in their Discord.
IPFS
Now, let’s talk about IPFS quickly. You might have seen us use IPFS for NFT data. IPFS is a fantastic tool for storing public distributed data. You place data onto an IPFS node, you get a hash, and then you can share that hash with others who run a node to verify the data. But it lacks data persistence. Anyone can add data to the IPFS network, allowing anyone to access it, but if no one keeps that data pinned, no one can get the data from a hash. And there is no incentive to keep someone pinning the data.
Because it’s such a quick and solid option for distributed data though, we did post our site to IPFS, and we have it pinned at least to our node. Our site could become unstoppable if people all around the world pinned the site themselves.
All we had to do was take the static export of the site and pin the whole folder onto IPFS, and now we can just place the CID into any browser that is IPFS-compatible, or any browser with an IPFS extension.
Filecoin
Now, here is where Filecoin comes in. Filecoin is a blockchain that adds an economic incentive for people keeping your data hosted, and adds data persistence on top of our IPFS hash.
However, even after running a node myself, using Filecoin in combination with IPFS right now is too difficult for my smol brain. So I hit up web3.storage to help me out. web3.storage is a centralized site that helps facilitate decentralized storage deals. It could block my deal going to Filecoin, and then I’d just have to go back to figuring out how to get a deal through a Filecoin node myself. But once I get my data onto Filecoin, I don’t need them anymore (hehe).
Similar to Sia, Filecoin uses “contract-based” data persistence, but instead of “encrypting” your data it “seals” it. This means it’s hidden from view, but anyone could pay a retrieval node to retrieve the data.
You can see the duration of how long our site will stay up on the Filecoin network by looking at the Filfox block explorer (or exploring our node). Filecoin nodes are also IPFS nodes under the hood, and can optionally pin the data to IPFS. We can then grab CID as well and drop it into our IPFS node to render the data that is stored on Filecoin.
You can think of Filecoin as like a giant marketplace, like Sia, where nodes are taking contracts and placing collateral to store your data. The blockchain then periodically challenges random nodes by asking for random pieces of data. If they drop the data, they are punished.
So we can be sure our website will be safe on Filecoin, and if we want to keep it there forever and also on an IPFS node, we just need to reinitiate the contract every time it’s up. You currently can’t go much longer than two years on a Filecoin contract, and the node is a lot bigger than a Sia node.
Filecoin is a terabyte large, which added to some of my frustration when running the nodes. Additionally, Filecoin doesn’t automatically pin data to IPFS, which is good, as we’d want to be able to store data on Filecoin as well, but most Filecoin nodes have the option to. We do run into a bit of a centralization problem there, as we have to trust our Filecoin nodes are going to pin our data, and there isn’t an incentive for them to pin the data. We could just have someone pay a Filecoin node to get the data and show the CID to make sure it’s the data we want, but those solutions are still being worked on.
So we run into the same problem Sia has—without a private key or access to the node ourselves, we are the only ones who can view our website if the nodes don’t pin our data. Or you have to pay for the data anytime you want to pull from the network.
Bringing It Back Around
So to make our site truly unstoppable, we:
- Took a snapshot of the site and stored it on Ethereum.
- Stored our site on the Arweave blockchain.
- Stored our site on the Sia blockchain so at least we can always access the site.
- Pinned it to IPFS ourselves.
- Had Filecoin nodes pin it to IPFS as well.
So we’re good, right? This is probably overkill, but we are making our site redundant by using multiple dStorage locations. The last thing we need to do is to have some type of mapping that says our `unstoppablefrog` site is mapped to these different dStorage locations.
And it would be great if we could have a human-readable version of our site instead of these crazy hashes.
Lucky for us, there is one chain that we know is solid, which we can use to map a human-readable name to these different locations—and that’s the Ethereum Name Service.
The ENS is a smart contract on the ETH blockchain where you can map human-readable names to these more complicated hashes. We bought a name called “unstoppablefrog.eth” and added our IPFS hash into the content section. There is a centralized server out there that maps `.eth` domains to whatever is in the content hash of the name, so if I put “unstoppable frog.eth” into the address bar, I get a rendering of our site.
If that server goes down, anyone can still come to the smart contract and get the hash themselves, so our data is permanently secured. If our IPFS hash goes down, we can look in the description section and see all these backups, and anyone could route to one of these descriptions instead of just pulling from the content. This provides a single canonical location for someone to read all the different decentralized locations where our data is stored.
Making our site, hopefully, unstoppable.
Tor
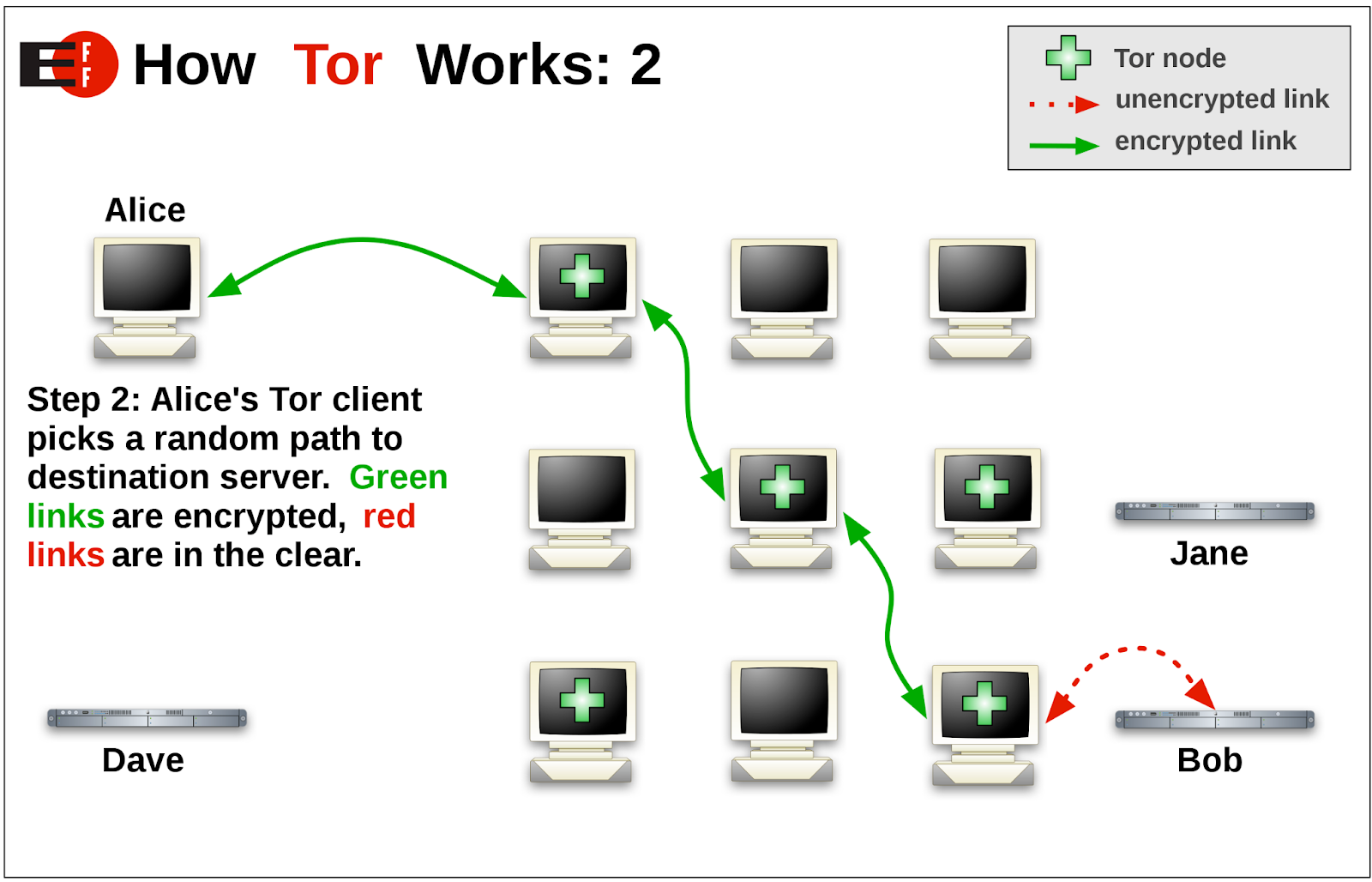
One final thing that we could do to add another layer to our unstoppableness is to add an onion address to our ENS data. An onion address is a website through the Tor browser, a peer-to-peer network that helps anonymize users. Placing our site on Tor would add one hosted location that’s difficult to take down.
Summary
I hope you learned a lot from this. The GitHub repo with all my code, experiments, and notes is below, and I’m looking forward to using dStorage as the database for my smart contracts in the future, with Chainlink as the middleware that connects the two.
GitHub: https://github.com/PatrickAlphaC/unstoppable-ui
Unstoppable website: https://unstoppablefrog.eth.link/



