Understanding How Data and APIs Power Next-Generation Economies
In the previous two Education Series articles, we discussed blockchains and smart contracts as new highly secure and reliable infrastructure for transferring and storing value. Like a computer without Internet, blockchain-based smart contracts have inherent value on their own, such as creating and swapping tokens. However, they become exponentially more powerful when externally connected to the vast and accelerating data and API economy taking root outside the blockchain ecosystem (off-chain).
Smart contracts can become the dominant form of digital agreement across all the major markets if they successfully tap into the vast data reservoir generated by data providers, web APIs, enterprise systems, cloud providers, IoT devices, payment systems, other blockchains, and much more.
In this article, we take a deeper look into data and APIs, specifically:
- What is data and how does it drive a data economy?
- How data is produced?
- How is data exchanged through APIs?
- What is Big Data analytics?
Understanding the full scope of the off-chain data economy sets the foundation for the next article where we will explore how to securely and reliably connect smart contracts to these resources using additional infrastructure known as ‘oracles’.
Data and The Data Economy
Data
Data are characteristics or information obtained through observation, such as measuring the temperature outside, calculating a car’s location, or documenting a user’s interaction with an online application. On its own, raw data is not particularly valuable or reliable; it needs other data to contextualize it and conformation to ensure its validity and/or veracity.
Metadata
Metadata is “data about data” that mostly consists of basic information to make tracking and working with data much easier. For example, the send time of a text message, the geographic location of a temperature reading, or the duration of a phone call are all metadata that helps index and give meaning to data.
Data Cleaning
Additionally, data needs to be processed and cleaned in order to be reliable enough to be used by mission-critical applications. The cleansing process involves removing outliers, spotting inaccuracies, and disregarding irrelevant information; e.g. comparing current temperatures to historical temperatures to spot and prevent the use of outliers.
Data Economy
The data economy is an economic ecosystem in which all types of data is gathered, refined, and exchanged in ways that produce valuable insights. These insights are then used to maximize societal output — a shared health database for storing clinical trials to better understand medical conditions or a private company tracking its internal operations to identify and improve upon inefficiencies.
The growing data economy is opening up new possibilities around automation in which data leads directly to the triggering of economic actions without human intermediaries. For example, creating an application that makes a payment for goods once three pieces of data are confirmed: the goods arrived (GPS data), they are in good condition (IoT data), and they passed customs (web API).
Data Production
Data is a byproduct of a process or event. It needs an input (action) to generate, an extraction (measurement) technique to record, and an aggregation technique (analysis) to give it meaning. Because access to specific inputs and extraction/aggregation techniques can be limited in accessibility, not all data is created equal nor does everyone have the ability to create the same quality of data.
Some of the most common ways to capture new and original data include the following:
- Forms (Manual Input) – data captured by users manually filling out public or private forms, such as participating in surveys, signing a document, and engaging in social forums.
- Applications/Websites (Usage Consent) – data is captured by users’ agreeing to the terms and conditions of an application or website, which generally grants legal consent to track certain data metrics like app-specific activity, browsing habits, and sometimes even general profile information (gender, age, etc).
- Internet of Things (Real-time Monitoring) – data captured by devices equipped with sensors and actuators that transmit data via the Internet, including smartphones, smart home appliances, health wearables, RFID-tracked goods, and more.
- Proprietary Processes / Individual Experiences (Ownership) – data captured through a company’s ownership over a business process (having a patent or being the market leader) or from someone’s unique personal experience.
- Research and Analysis (Combination and Interpretation) – data captured by taking existing data sets and providing some original interpretation to them: cross-examination against historical data, cross-reference against other data sets, new filtering and calculation techniques, etc.
There also exist data resellers, who buy data in bulk from data aggregators or valuable companies and then resell it to end-users. While more expensive, data resellers preprocess data to fit customized filters or formats.
Data Exchange
If data is to become a core building block for next generation applications, then industries require marketplaces to buy and sell data instead of relying solely on in-house production. Buying data can be substantially cheaper than producing data. For example, creating a self-driving car algorithm requires an extensive amount of data on object detection, object classification, object localization, and predictive movement. To obtain this data, the developer could produce it internally by driving millions of miles or simply purchase it externally through an API.
An Application Program Interface (API) is a set of instructions on how an external application can access specific datasets and/or services within your system. APIs are the standard method of buying and selling data and services today. Popular ride-sharing app Uber uses a GPS API for location data (MapBox), an SMS API for messaging data (Twilio), and a Payments API (Braintree) for payment data to manage common app functionalities rather than build each one of these services from scratch.
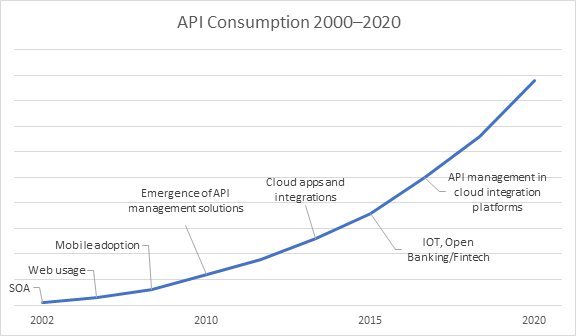
APIs are monetized usually through subscription plans where end-users pay per use (metered), take on standard monthly plans (licensed), or agree to some form of tiered billing. This creates monetary incentives for data providers to produce data, while end users consume it without the need to provision their own infrastructure. It also establishes a legally binding contract between the API provider and paying users to prevent malicious activity such as pirating data and reselling it without permission, as well as to hold the data provider accountable to certain performance standards.
There exists a variety of APIs that are open and free for anyone to access including Open Weather Map for weather data, Skyscanner Flight Search for flight status data, and GDELT for worldwide human behavior and beliefs. Additionally, governments around the world are making an increasing amount of data available via open APIs as part of their open data initiatives.
However, open APIs are not as reliable as paid APIs because they lack financial incentives and legal contracts that are tied to quality control and latency performance. The vast majority of high-quality data is obtained through paid APIs, which generally have access to the primary data source, own full stack infrastructure, employ full time monitoring teams, and innovate constantly to compete with other data providers for business.
Big Data Infrastructure and Analytics
Humans have been fascinated by the idea of programming systems in a manner in which they can learn and self improve. Learning is facilitated by taking an action, receiving a result, analyzing it against historical data, and gaining new insights about how to better perform in the future to achieve a specific goal. As such, there has been a megatrend around building infrastructure that can take in a massive amount of data, filter it, categorize it, and gain deep insights from the results.
Facebook, Google, and Amazon in the West along with Alibaba, Tencent, and Baidu in the East have become tech giants because their widely used internet applications produce massive data reservoirs from their users. This data forms the foundation for the world’s best data analytics, particularly artificial intelligence (AI) and machine learning (ML) software. These technologies give extensive insights into consumer behavior, social trends, and market practices.
At the same time, business management software helps enterprises better understand their own operations. Companies like SAP, Salesforce, and Oracle have built Enterprise Resource Planning (ERP), Customer Relationship Management (CRM), and Cloud Management software that help companies manage their internal business processes by compiling all their data and systems in order to generate key insights.
Cloud computing and storage have also become increasingly popular as a way to get more reliable and extensive access to digital infrastructure. Cloud computing allows many different users to share infrastructure for storing and processing data, removing the need for each of them to provision and run their own systems. It has improved the backend processes of applications, increased sharing between systems, and reduced the costs to access AI/ML software. For example, Google Cloud users can take advantage of BigQuery, a Software-as-a-Service for scalable analysis of petabytes of data with built-in ML capabilities.
Moving Towards The Fourth Industrial Revolution
When we combine AI/ML, business management software, and cloud infrastructure, it results in better tools for enhancing the insights derived from data. Further adding to these trends is edge computing, 5G telecommunication networks, and biotechnology, which open up increasingly real-time and biologically connected data environments. These systems are continually moving economic systems towards real-time data-driven decision making with less human effort, especially as data is produced and shared in a seamless, more frequent manner. In fact, many are referring to this megatrend as The Fourth Industrial Revolution.
Further Reading
Learn more by checking out the next article in the Education series about the “Oracle Problem”. Follow us on Twitter to get notified of upcoming article releases and join our Telegram for the latest news on Chainlink.



