Recent advancements in large language models (LLMs) and AI agent systems suggest a transformation in automated information processing capabilities. This evolution could enable new applications in automated verification systems. Among these emerging applications, AI Oracles* present a promising approach for automatically sourcing and verifying factual information from diverse sources, including documents, internet content, and openly available data. Like OpenAI’s Deep Research system, which autonomously researches and analyzes information, AI Oracles have the ability to bring automated truth verification to decentralized systems with enhanced transparency and potential for increased reliability through model consensus mechanisms (e.g., decentralized oracle networks as seen in Chainlink). By leveraging cutting-edge AI and decentralized mechanisms, AI Oracles would transform how we verify real-world data, ensuring trust and transparency in automated systems.
The potential applications of such systems appear significant across multiple domains. In prediction markets, these systems could enable reliable resolution of events, ranging from political outcomes to scientific breakthroughs. For parametric insurance applications, preliminary research suggests these systems could accelerate claim processing through automated verification of weather events, natural disasters, or flight delays.
While initial demonstrations with large language models show promise, developing reliable, battle-tested systems that address the non-deterministic nature of AI technology remains challenging. This reliability requirement becomes particularly significant in blockchain applications, where decentralized truth verification necessitates unbiased, computationally verifiable outcomes.
This paper presents an empirical validation approach through large-scale testing using real-world prediction market data from Polymarket—a decentralized prediction market platform built on the Polygon blockchain. The proposed system processed 1,660 betting outcomes from individual markets with trading volumes exceeding $100,000 USD, providing insights into AI Oracle capabilities within high-stakes scenarios.
*Oracles are external agents that perform a computationally verifiable service on behalf of blockchain-based smart contracts or offchain systems, generally by retrieving data, computing upon it, and delivering it to a destination. Decentralized oracle networks perform these services using consensus-based computing to prevent single points of failure and improve resiliency and accuracy.
Technical Implementation Details
System Architecture and DSPy Framework
We created a basic LLM-enabled oracle that leverages DSPy[1], a pioneering framework from Stanford NLP that revolutionizes how AI systems are built and optimized. Born from research into compound language model systems, DSPy has demonstrated its versatility through successful implementations like Haize Labs’ automated red-teaming[2] system and Replit’s code repair solution[3]. The framework’s declarative programming model enables focus on “what” rather than “how” through signature-based development, while its module system provides structured components like ChainOfThought[4] for reasoning. DSPy’s built-in optimization framework supports automatic few-shot example generation and self-improving prompts, making it particularly effective for complex decision-making tasks like market resolution.
Our architecture leverages these DSPy capabilities across three core components, shown in the diagram below:
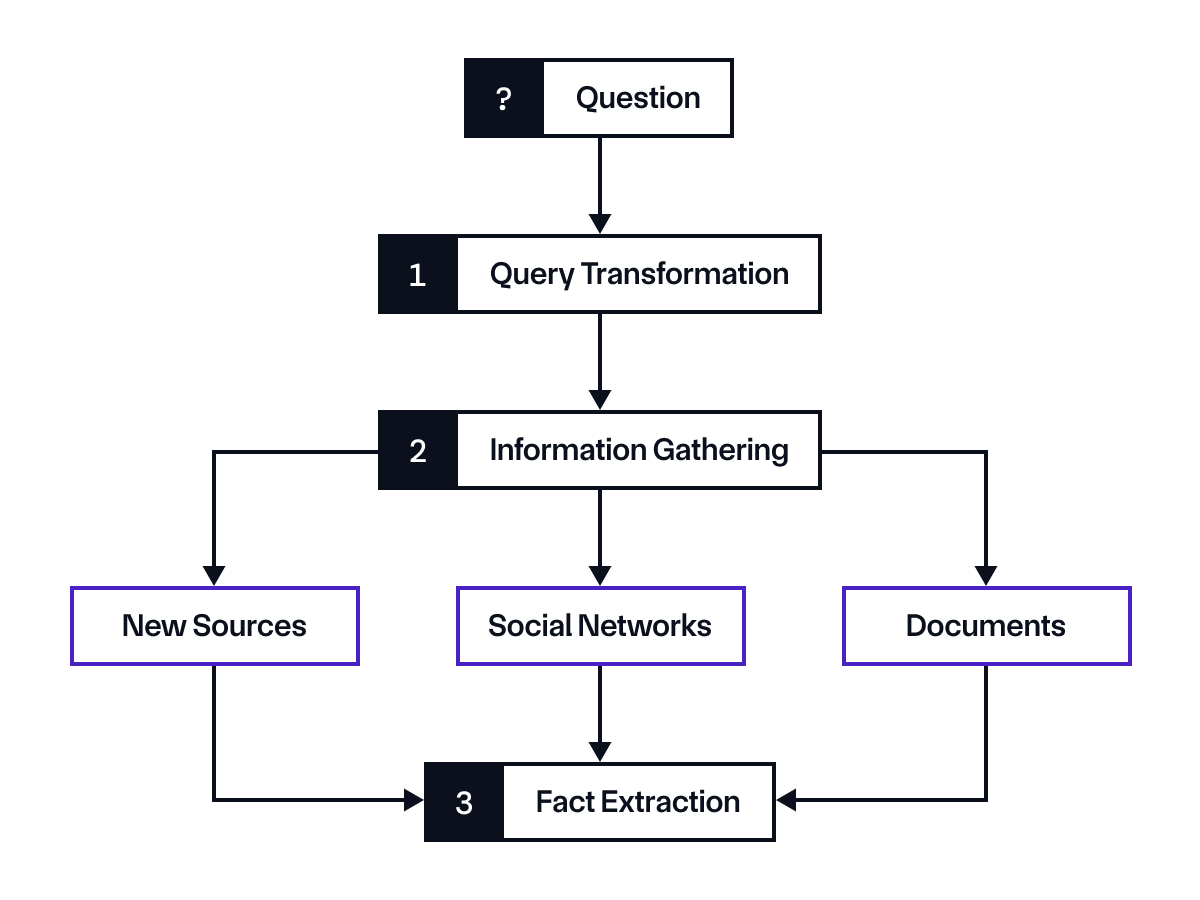
- Question Transformer Module: The Question Transformer Module harnesses Chain-of-Thought reasoning to transform market queries into temporally precise, context-rich formats optimized for information retrieval. This allows the AI agent to maintain critical market context resolution conditions while ensuring consistent question processing across all inputs.
- Information Gathering Module: The Information Gathering Module serves as the foundation for verifiable information processing through comprehensive web scraping powered by services like Perplexity or Google’s Gemini. By collecting complete webpage content from citation sources rather than relying on API-provided excerpts, we establish robust source grounding and maintain full transparency in our information gathering process. The extracted content serves as the grounding context for the Fact Extraction Module, where our system maintains precise control over both information grounding and context positioning—factors that have shown to reduce hallucination and improve model performance[5,6]. This approach ensures that each market resolution query is fully transparent and firmly grounded in verifiable sources.
- Fact Extraction Module: The Fact Extraction Module serves as the system’s analytical core, employing reasoning to process gathered information and determine market outcomes. Through explicit reasoning traces, it maintains a transparent decision-making process that can be audited and verified along with the contexts. The module’s structured approach ensures consistent evaluation across diverse market types while providing detailed reasoning for each resolution decision.
Quality Control and Evaluation
Our rigorous evaluation framework combines comprehensive data validation with systematic testing protocols. We carefully curated our test dataset from Polymarket’s API, selecting high-stakes markets with trading volumes exceeding $100,000 USD to ensure meaningful results. Each market underwent thorough preprocessing, including validation of question IDs and resolution outcomes, establishing a robust foundation for our empirical analysis.
The evaluation pipeline implements automated accuracy assessment through DSPy’s evaluation framework, employing exact-match validation for answer verification. Every market resolution follows a multi-stage validation process: initial data verification, source validation, and outcome confirmation. This methodical approach has enabled us to successfully process and validate 1,660 real-world market outcomes, creating a substantial and reliable dataset for analysis.
To ensure transparency and reproducibility, our system maintains detailed records of each evaluation, including comprehensive reasoning traces and model metadata. These results are persistently stored, allowing for thorough analysis and verification of our findings.
Real-World Results and Insights
The empirical testing suggests promising capabilities for AI Oracle applications in real-world scenarios. The empirical testing demonstrates the system’s capabilities in verifying real-world events and outcomes. Using GPT-4o, our system achieved an overall accuracy rate of 89.30% across diverse verification scenarios. Breaking down performance by category reveals interesting patterns: sports-related verifications achieved the highest accuracy at 99.7%, followed by cryptocurrency events at 85.0% and political outcomes at 84.3%. The system showed particular strength in discrete event verification where outcomes had clear, official sources of truth.
A successful verification example involved determining the winner of an NFL game, where the system correctly processed official game statistics, post-game reports, and verified news sources to reach an accurate conclusion. In contrast, the system showed lower accuracy in cryptocurrency and political categories, particularly when dealing with complex financial thresholds or ongoing political developments where temporal boundaries were less defined.
These preliminary results indicate potential viability for complex market resolutions while maintaining systematic verification processes.
Key Learnings
Analyzing evaluation results revealed important insights about how LLMs process temporal information. Our initial evaluation results revealed that question framing significantly impacts system performance, which appears to stem from fundamental limitations in how LLMs process temporal information. The empirical evidence suggests that these models lack robust temporal cognition—specifically, they struggle with the concept of relative time and maintaining awareness of when information was created relative to the events being verified. While discrete events with clear outcomes and readily available official sources can be verified with exceptional accuracy (as seen in sports), scenarios involving continuous monitoring or complex temporal relationships present ongoing challenges. This limitation manifests in confusion when processing web-sourced information that contains mixed temporal references or requires understanding of chronological relationships.
By restructuring queries to provide explicit temporal frameworks and clear chronological anchors, we observed consistent improvements in system accuracy. The Question Transform module’s ability to construct temporally precise queries appears to compensate for the model’s inherent limitations in temporal reasoning, providing clearer context for information processing and verification. In our testing, questions processed through temporal standardization showed significant improvement in the model’s ability to ground its responses in the correct timeframe compared to baseline queries. This finding suggests that while current LLMs may lack inherent temporal cognition, carefully structured inputs can help mitigate these limitations.
In examining cases where the system encountered challenges, a consistent pattern emerged around questions involving temporal reasoning—particularly when verifying sequential events or tracking statements over time. For example, the system struggled with questions like:
- “Did Elon Musk tweet about Dogecoin more than 3 times in March?”
- “Was the interest rate hike announced before or after the GDP report?”
where temporal aggregation and precise chronological ordering of events was required, respectively. These findings align with broader research observations about LLMs’ difficulties in handling temporal dependencies and chronological relationships[7].
These findings suggest several fundamental challenges in current AI Oracle systems. First, there appears to be a misalignment between how information is typically presented on the Internet and how AI systems need to consume it. For instance, transcript content might be formatted as video captions, need to be transcribed from video, or presented within broader articles that prioritize narrative flow over structured data.
Furthermore, the information available online tends to reflect human interest patterns rather than AI analytical needs. News articles and public content rarely focus on quantitative aspects like word frequency counts or precise chronological ordering of related events, as these aren’t typically of interest to human readers. This creates a significant challenge when AI systems need to verify specific temporal claims or aggregate historical data points.
Future Directions
Building on these empirical findings, our research suggests several promising pathways for improvement. We are exploring fundamental improvements in how we query language models themselves. Taking inspiration from advanced systems like Baleen[8], we envision queries that go beyond simple transformations to incorporate rich contextual awareness. This approach would embed crucial elements—such as temporal anchors, verification requirements, and market-specific context—directly into the query structure, potentially improving both information retrieval precision and overall system accuracy[9].
In parallel, our extensible architecture presents an opportunity to enhance output reliability by leveraging decentralized oracle networks (DONs). By distributing the system across DONs, we would enable multiple independent verifications—each grounded in diverse sources and utilizing different reasoning models—to be aggregated through a proven consensus protocol. Such an approach could significantly improve both reliability and consistency in high-stakes scenarios where accuracy is paramount.
At the same time, we recognize a fundamental challenge: as language models advance, they increasingly share training datasets and could potentially exhibit similar biases. This observation has led us to question whether consensus mechanisms alone—simply aggregating outputs from different models—can effectively mitigate these biases.
Consequently, we believe there is a need for dynamic source credibility systems that move beyond static “approved source” lists. This system will evaluate and rank information sources in real time, considering diverse perspectives ranging from national to cultural boundaries. We believe that fixed definitions of credible sources may not withstand the test of time, especially in our rapidly evolving information landscape.
Conclusion
Our empirical testing provides valuable data points for the growing AI Oracle field. An 89% accuracy rate across 1,660 real-world cases demonstrates the current capabilities while highlighting specific areas for continued development. Rather than relying solely on model consensus, we’re developing sophisticated context-aware query understanding techniques that maintain temporal precision while enhancing information retrieval accuracy. This architectural flexibility, combined with our empirical approach to validation, positions us well to continuously enhance the system’s capabilities while maintaining its production reliability.
—



